Concurrent Scheduling
Haploid.js has been designed from the outset to optimize for concurrent scheduling to achieve the highest possible user response efficiency.
What is scheduling? We know that in micro-frontend architectures, the loading and unloading of sub-applications is often controlled by user actions, such as clicking links and buttons, or clicking the browser to go forward and back. We can call this operation an instruction.
The micro-frontend system needs to process this instruction to decide which subapplication to load, and thus all other sub-applications to unload. However, sub-applications are often loaded and unloaded asynchronously, and they often do not respond to instructions immediately.
Therefore, the system needs to have a mechanism to cache all instructions and decide when to process instructions based on some principles, such as having to wait until the previous sub-application is unloaded before loading the next sub-application to avoid conflicts. In addition, the system may need to identify which instructions are obsolete and should be discarded, such as when the "loading A" instruction has not yet started processing, and the "load B" instruction is received, then it is clear that "loading A" is an outdated instruction.
This kind of micro-frontend mechanism described above is called scheduling. Let's take another image example.
The earth🌍 controls the rover far away on Mars👽, due to the distance factor, there will be a long delay in the middle of the instruction, often the previous one is still on the road, the earth has issued a new instruction.
What should the rover do with these instructions?
- First, check whether the executing instruction has expired
- How can the new instruction be mutually exclusive with the currently executing instruction, then the current instruction is expired, may need to interrupt it, may need to wait for its execution to complete, this process may take some time;
- If there is no mutual exclusion, then it can be executed concurrently
- Second, check whether the next instruction is expired
- Before executing the next new instruction, check whether the latest received instruction is mutually exclusive with the instruction. If they are mutually exclusive, discard the instruction immediately
Obviously, like our micro-frontend, it can be understood as a classic asynchronous task processing system with shared resources. Micro-frontend needs the system to respond to the latest operation instruction of the user as soon as possible, without caring about what the user did before this instruction.
Then we must dig deep the relationship between the instructions, so that the expired instructions exit as soon as possible, in order to speed up the response.
How to tell if instructions are mutually exclusive?
In general, if different instructions have the possibility of operating on the same resource (such as memory), then they are mutually exclusive. Two instructions that attempt to write data to the same row in the database are obviously mutually exclusive, otherwise they will cause inconsistent results.
The essence of mutual exclusion is competition, and there are at least two ways to resolve this competition:
- Locks on resources;
- Locks on instructions
The former is suitable for databases because databases, as a highly aggregated resource, can handle a wide variety of instructions when implemented on a single node.
The main competitive resources in the field of micro-frontend are that it is impossible for two DOM sub-applications to create their own DOM structure at the same mount point, which may also include urls, and it is impossible for both sub-applications to require the browser's address bar to match their own.
You can also think of other resources, such as localStorage, WebSocket, etc., these resources are characterized by decentralization, there is no way to uniformly lock to deal with different sub-applications of race access, so the simple and effective way is not to allow two sub-applications to be activated at the same time, that is, lock on the instruction you have to uninstall B before load A.
However, the execution of the instruction is asynchronous, when the uninstall B is issued, B may be loading, or it may be executing other instructions, do or do not wait for it to complete?
Wait or not, and involve the same application internal competition for resources, the specific results are more complex, for example, uninstall an application that is loading what happens? It's possible that the loading process stops, but it's also possible that it recreates the DOM, which we don't want to do so the most conservative thing to do is wait for the loading to finish and then unload, which is the usual instruction scheduling strategy: one instruction waiting for another, the queue model.
But this may need to wait too long, for example, in the single-spa model, bootstrap is the stage of downloading remote resources, which takes longer, and it will seriously affect the subsequent instructions.
If we can determine and even narrow the time interval between competing instructions, then obviously they don't have to be mutually exclusive and wait throughout the timeline.
Interruptible Instructions
Look at the diagram below, Haploid.js uses such a side-effect interval model, that is, the instructions are not completely exclusive, but there is a side effect interval, as long as only one instruction is running in this interval, then the two instructions have a certain degree of coincidence on the timeline.
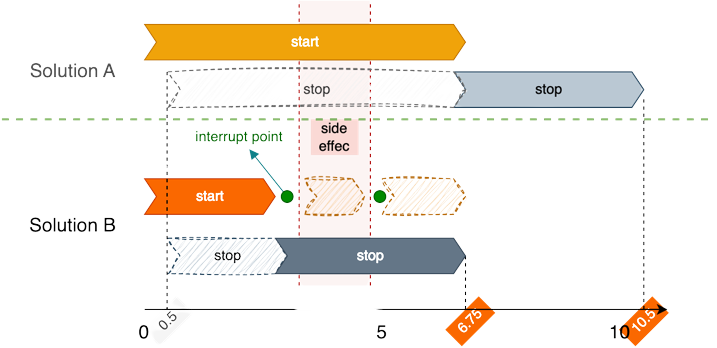
Take a look at the first half of plan A and observe the horizontal axis time line at the same time, the start instruction is being executed. Suppose that the stop instruction is issued at 0.5s, and then stop is executed after the start execution is completed, which takes 10.5s in total.
Now we design multiple breakpoints during the execution of the instruction, and once we get there, we check to see if it is necessary to exit. For solution B start, when executing the first breakpoint, a new stop instruction is found, so start should exit immediately and stop starts executing. The whole process takes 6.75s.
If start exits at the second breakpoint, stop should be delayed accordingly, but always faster than in plan A.
Haploid.js requires instructions to be asynchronous, which also conforms to the single-spa specification. Breakpoints are therefore easy to design.
Specifically, Haploid.js has the following effects:
- The bootstrap lifecycle process of one sub-application does not block any lifecycle of any other sub-application, and Haploid.js assumes that bootstrap does not cause side effects;
- Issuing successive load and unload instructions for the same application does not execute the load process, and vice versa;
- During loading and updating, the app may be interrupted to respond to unload instructions as quickly as possible, see safe mode
Summary
Haploid.js uses the side effect interval model to describe the mutual exclusion state between instructions and shorten the time of mutual exclusion as much as possible, so as to advance the execution of instructions and speed up the reaction speed of the system to user operations.
The above instructions refer to the various lifecycle functions at the sub-application layer: bootstrap, mount, unmount, and update, which are exactly the same as single-spa. Haploid.js is further abstracted into four instructions with scheduling capability: start, stop, update and unload. The approximate corresponding relationship is:
start => bootstrap+mount
stop => unmount
update => update
unload => unmount
So, if the start instruction is executing bootstrap, stop and unmount don't have to wait for it to finish.
TIP
That's how concurrent scheduling works, essentially reducing the granularity of instructions to find as many times as possible to execute in parallel.
The disadvantage of this implementation is that it makes the instructions more coupled to each other, and if new instructions are added in the future, then the relationship with the existing instructions needs to be traversed.